
Why you should be annotating in-house
Raza Habib
Why you should be annotating in-house

Deep learning is only as good as the data it’s trained on, so text labeling is a crucial step for ensuring the accuracy of Natural Language Processing (NLP) models. Most data science teams used to outsource data labeling; it was the only way to achieve the scale they needed. However, recent breakthroughs in new techniques like programmatic supervision, active learning, and transfer learning have reduced how much annotated data you need and made in-house annotation more practical. The quality of your data is more important than quantity, so if you can annotate in-house, you probably should. It allows you to have better control over quality, handle privacy more easily and make better use of subject-matter expertise.
In this blog post, we review how people used to label and discuss the recent breakthroughs that are making in-house labeling practical and affordable.
What is text labeling and why is it important?
Most of the machine learning methods applied today are supervised. This means that to train an artificial intelligence (AI) model, you need a dataset where a human has provided examples of what you want the AI model to do. For text, you usually need some amount of domain expertise. Some common types of annotation are:
- Classification: Where the annotator assigns one or more categories to an entire document. For example you might want to know the sentiment of a tweet or the intent of a customer speaking to a chat bot.
- Entity or Token Annotation: Where the annotator assigns labels to individual tokens or words in sentence. This is commonly used to find named entities or for information extraction.
The reason that text annotation is so important is that your machine learning model is trained to mimic what the annotators do. If the annotations are inconsistent or incorrect, then these mistakes will degrade the performance of your model.
Text annotation might seem simple, but often there are nuances to what the correct annotation should be. For example, in sentiment labeling, different people might reasonably disagree about the sentiment of an example sentence. Trying to get an entire team of annotators to label a dataset perfectly consistently and quickly is usually the biggest challenge in text labeling.
Why did teams used to outsource annotation?
Until recently most teams building NLP models would outsource their annotation to service providers like Mechanical Turk or Scale AI.
This was because data scientists often needed vast quantities of labeled data – potentially hundreds of thousands of human-provided annotations. To get this many labels from an in-house team was often too much work. It would usually mean hiring a lot of people, training them, and creating custom annotation software. Few teams other than the mega-tech companies that had a lot of funding were willing to do it.
There are big downsides to outsourced annotation, but the largest are that it’s much harder to control quality, and private data requires special data sharing agreements. Outsourcing companies also don’t usually have the domain knowledge you need. However, when you needed hundreds of thousands of annotations, it just wasn’t practical to do it in-house.
What’s changed to make in-house annotation possible?
In the past two to three years, there have been three big breakthroughs that have made in-house annotation not just feasible but the best choice for most teams. The big breakthroughs were:
- Transfer learning for NLP: Starting in 2018 a huge new breakthrough began in NLP. Instead of training a model from scratch for every problem, it became possible to use pre-trained models and specialize these to your task. The first paper that got this technique to work was called ULM-fit but since then models like BERT and other transformer models have become very popular. Specializing a pre-trained model is called fine-tuning and it often only requires a few hundred labels to get great results.
- Active Learning: Active learning is a technique that allows you to work out what data is most valuable to label. Most datasets contain redundant information or noise. Active learning focuses your annotation efforts on the data points that will have the most impact and so makes sure that every label you make actually improves your model.
- Programmatic Supervision: Programmatic supervision avoids manual annotation altogether. Instead of applying labels by hand, you use approximate rules to annotate the data. Once the rules are applied, a model is used to combine all of the noisy sources of supervision together into a single clean dataset.
Taken together these changes make it possible to train state-of-the-art models with datasets of only a few hundred labels. Getting this many labels is much more feasible and is driving a trend towards in-house annotation.
How can you do this in practice?
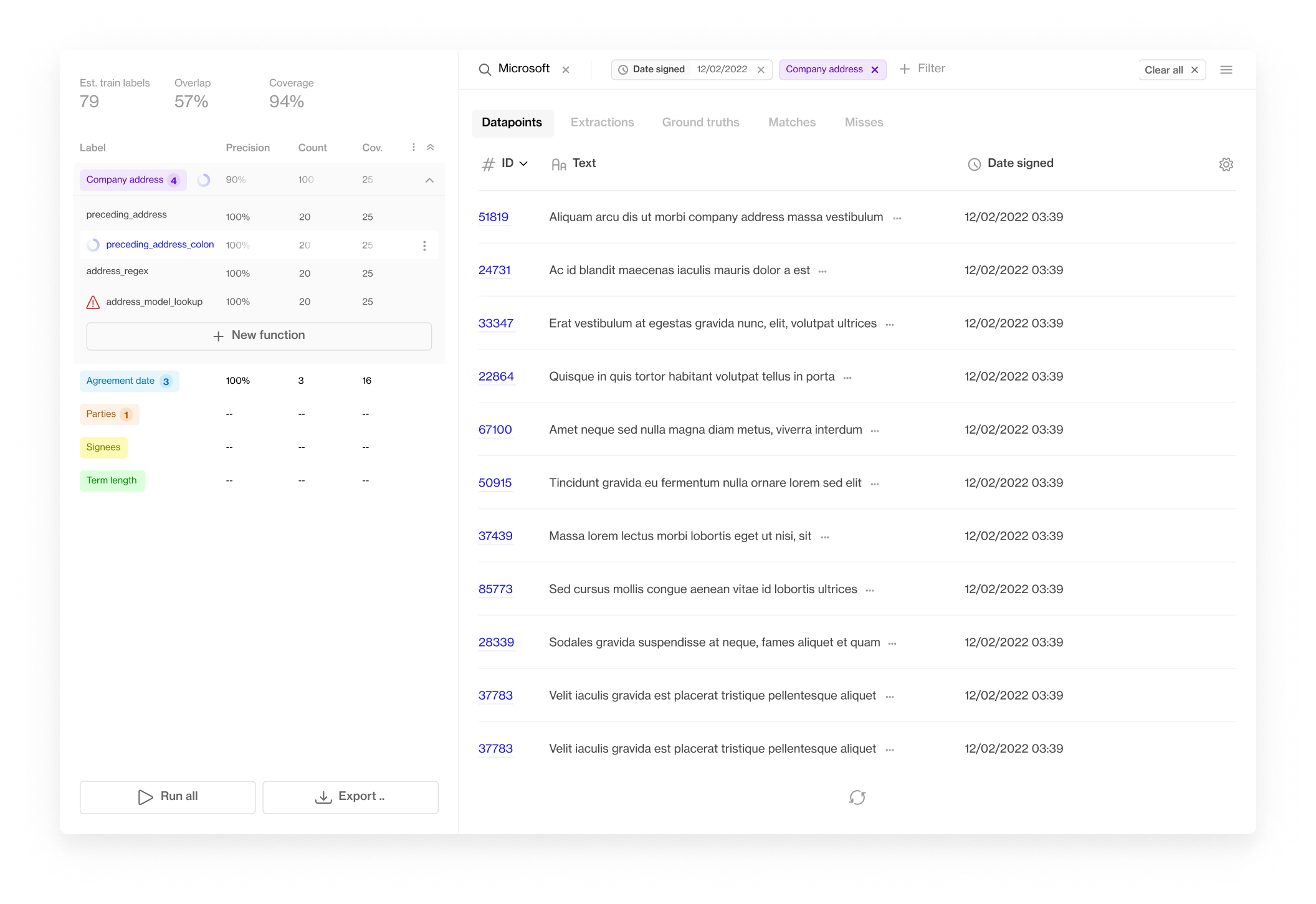
If you want to annotate data for NLP in-house, you’ll probably need annotation software. There are a bunch of solutions that offer annotation interfaces but if you want the benefits of things like active learning and programmatic labeling your options are more limited.
At Humanloop we built Programmatic to solve some of these UI/UX issues associated with other solutions. Programmatic lets machine learning engineers get a large volume of annotated data quickly by providing a simple UI to rapidly iterate on labeling functions with fast feedback. From there you can export your data to our team based annotation tools to annotate with active learning or use the data with other popular libraries like Hugging Face.
Programmatic is free forever! Try it now here.
- Transfer learning using pre-trained models reduces the number of labels needed.
- Active learning focuses your annotation efforts on the data points that will have the most impact and so makes sure that every label you make actually improves your model.
- Programmatic supervision gets you a large annotated dataset really quickly. Using approximate rules to annotate all your data, a model is used to combine all of the noisy sources of supervision together into a single clean dataset.
Our team-based Humanloop platform is powered by active learning to ensure the highest efficiency in your annotation.

